
Distributed Computing
As we know from Chapter 1, Big Data is data whose volume, velocity, and variety requires innovative forms of information processing. In this chapter, we want to discuss in greater detail why this is the case and how Big Data can be processed.
The foundation of any large computational effort is parallelism. There is a famous quote from computer science pioneer Grace Hopper: "In pioneer days they used oxen for heavy pulling, and when one ox couldn't budge a log, they didn't try to grow a larger ox. We should be trying for bigger computers, but for more systems of computers. In other words, large tasks can only be solved by pooling resources. There are three general methods for the parallelization of computational tasks.
Parallel Programming Models
First approach message passing tasks are executed independently in isolated environments. Whenever these tasks want to communicate, they send messages to each other. This way, the tasks can exchange data between each other, e.g., because the data is required by different parts of the computation. This communication can be done locally on one physical machine, by using the provided functions by the operating system, or remotely in a distributed environment by communicating via the network.
The second approach is shared memory. In this case, the computational tasks are not performed in isolated environments, but share a common address space in the memory, i.e., they can read and write the same variables. Interactions between the tasks happens by updating the values of variables in the shared memory. Sharing memory within a single physical machine is directly supported by the operating system, and may even be a property of the model for parallelization (threads share the same memory, processes not). Sharing memory across different physical machines is also possible, e.g., via network attached storage of other networking solutions, but usually has some communication overhead.
The third approach is data parallelism. Similar to message passing, tasks are executed independently in isolated environments. The difference to message passing is that the tasks do not need to communicate with each other, because the solution of the computational tasks does not require intermediary results of other tasks. Thus, the application of data parallelism is limited to problems where this strong decoupling of tasks is possible. Such problems are also called embarrassingly parallel.
Distributed Computing for Data Analysis
Since Big Data is to large too compute or store on single physical machines, we need a distributed environment for computations that involve Big Data. Before computational centers started to account for Big Data, the architecture of such a compute cluster was similar to the outline below.
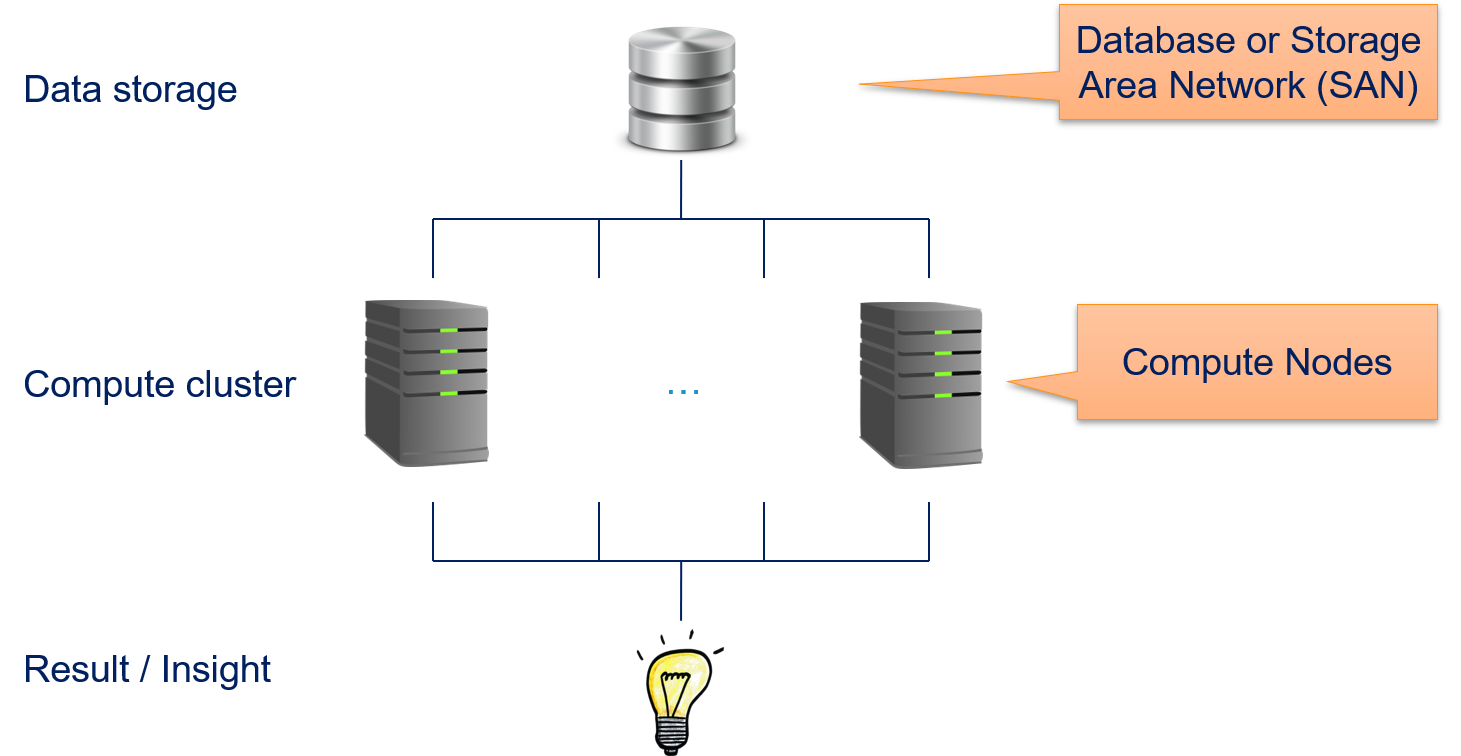
There is a layer for data storage and a layer for computations. Both are using different nodes in the compute cluster. Each node is a physical machine. Data storage nodes must provide fast storage (latency, throughput, or both), but do not require much computational power. This is usually implemented through database or a storage area network (SAN). Vice versa, compute nodes must provide the computational power through CPUs (and possibly GPUs) and a sufficient amount of memory, local storage is less important and often only used for caching and the installation of software. A user of such a system submits jobs to a job queue to gain insights. For the analysis of data, this means that the data is stored in the database or SAN and then accessed by the compute nodes to generate the desired results of the analysis, from which the data scientists can get insights.
All three parallelization modes we discussed above can be implemented in such a traditional distributed compute cluster. However, none of these approaches is suitable for big data applications in such a compute cluster. Message passing and shared memory have the biggest scalability problems.
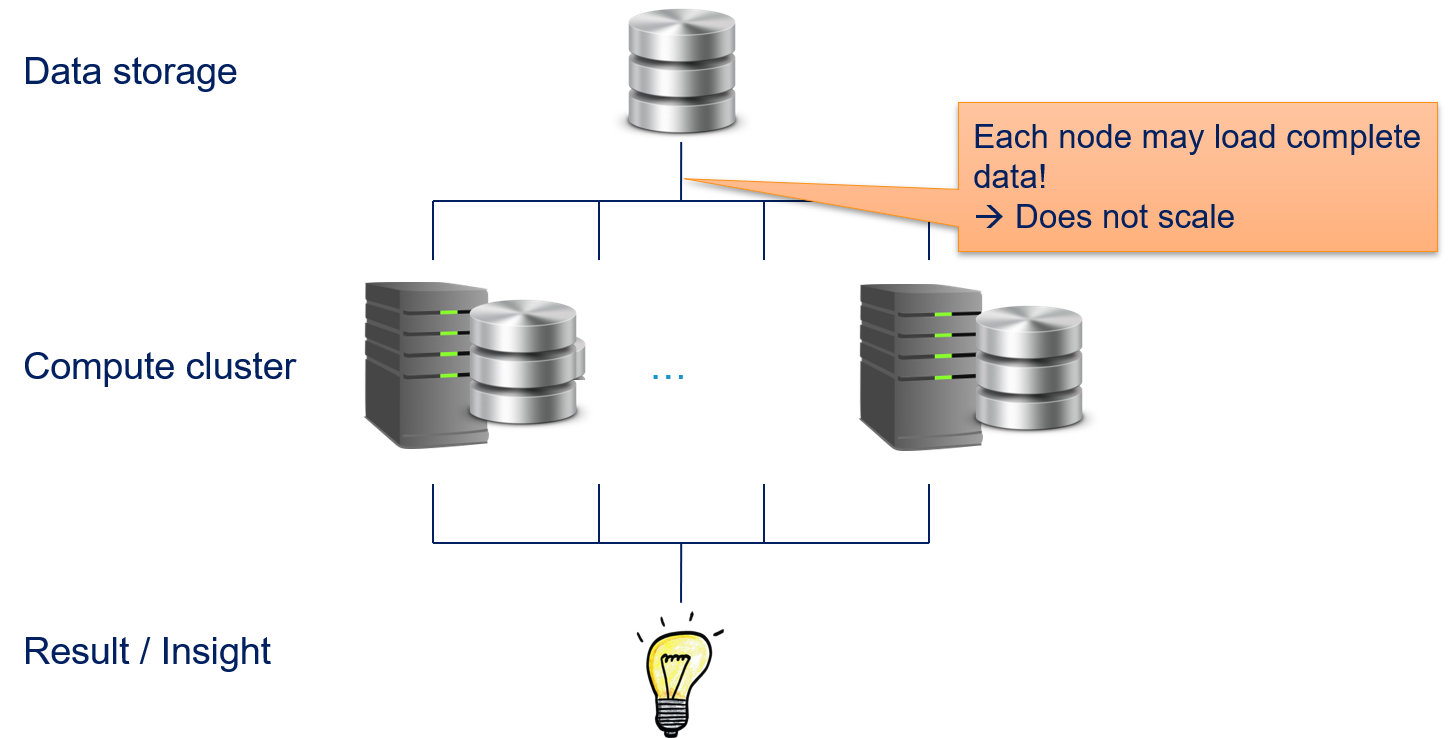
Since it is unclear which parts of the data are required by the different parallel tasks, it is possibly that every compute node must load all data. While this is not a problem for small data sets, this does not scale with large data sets. Imagine that Terabytes, or even Petabytes of data would have to be copied regularly over the network. The transfer of the data would block the execution of the analysis and the compute nodes would be mostly idle, waiting for data. This does not even account for additional network traffic due to the communication between the tasks.
Data parallelization fares a bit better, but also does not scale.
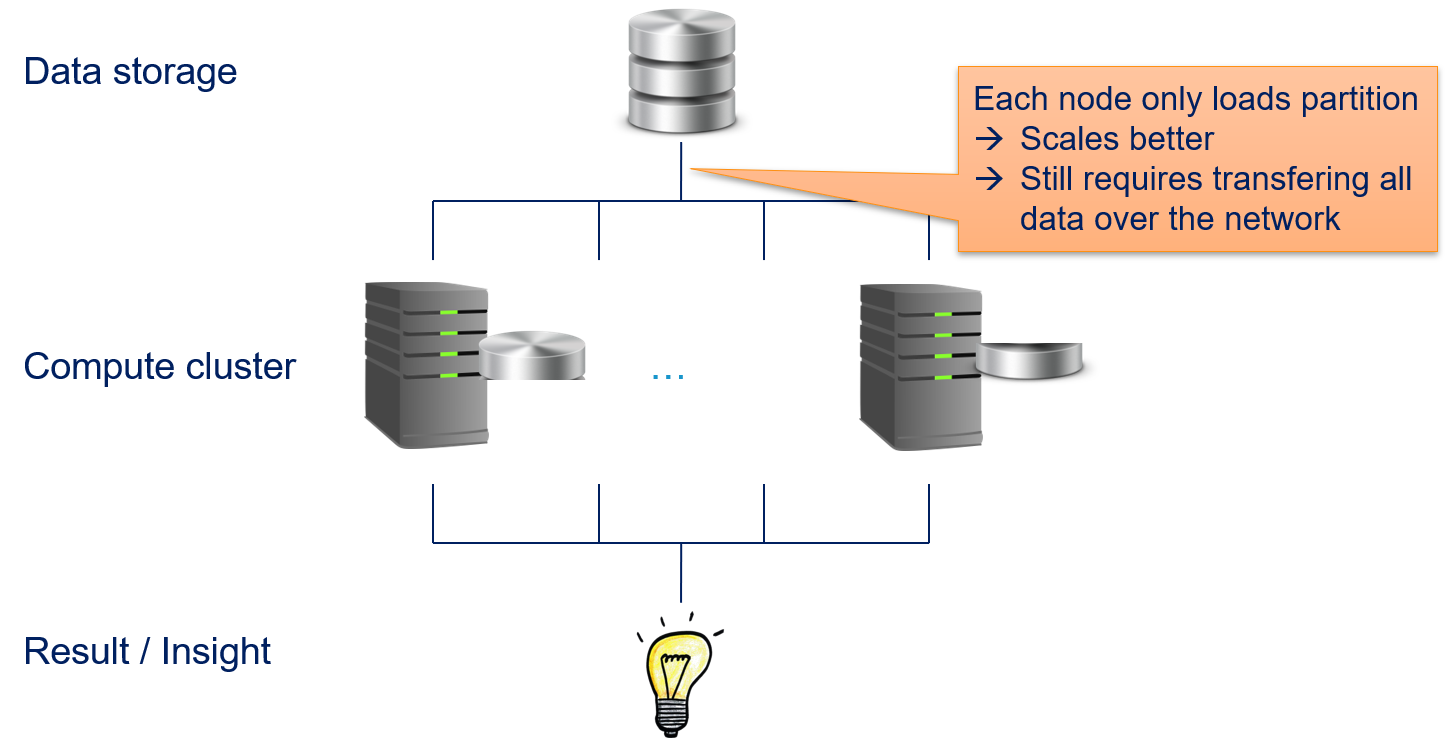
The advantage of data parallelism is that only parts of the data must be copied to each compute node. While this decreases the stress on the network, all data must still be transferred over network. Thus, data parallelization can handle larger amounts of data than message passing and shared memory, at some point the amount of data becomes too large for the transfer via the network.
Data Locality
We see that there is a fundamental problem with traditional distributed computing for big data, which is why we need the innovative forms of information processing. The solution is actually quite simple: if the problem is that we cannot copy our data over the network, we must change our architecture such that avoid that. The straightforward way to achieve this is to break the separation of the storage layer from the compute layer: all nodes both store data and can perform computations on that data.
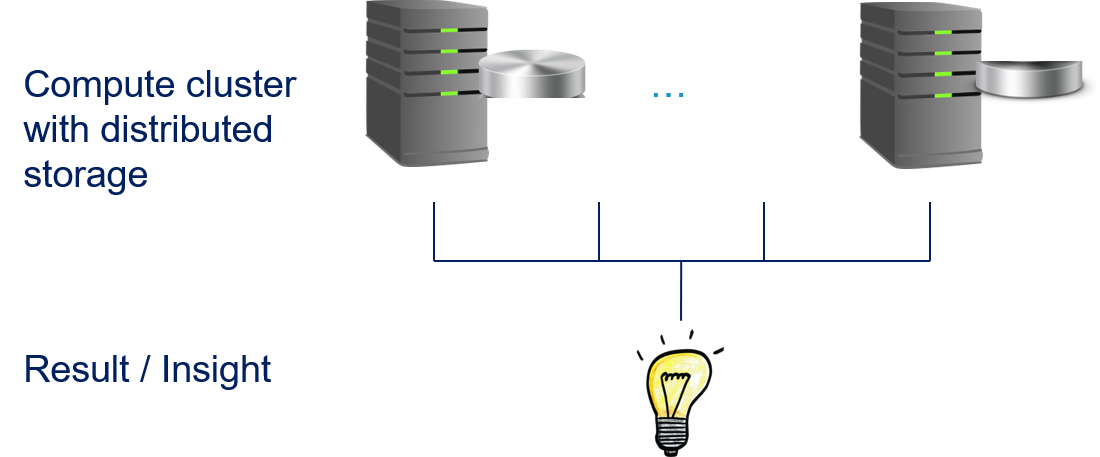
In the following, we explain how this is implemented in practice. We discuss the MapReduce programming model that became the de facto standard for Big Data applications. Then, we show Apache Hadoop and Apache Spark to demonstrate how the distributed computing with Big Data is implemented.
MapReduce
The MapReduce paradigm for data the data parallelization to enable Big Data processing was published by Google in 2004. The general idea is to describe computations using two different kinds of functions: map functions and reduce functions. Both functions work with key-value pair. Map functions implement the embarrassingly parallel part of algorithms, reduce functions aggregate the results. The concept of map functions and reduce functions is not unique to MapReduce, but a general concept that can be found in many functional programming languages. To enable Big Data, MapReduce introduces a third function, the shuffle. The only task of the shuffle is to arrange intermediate results, i.e., to facilitate the communication between the map and reduce functions. The following figure gives an overview of the dataflow of MapReduce.
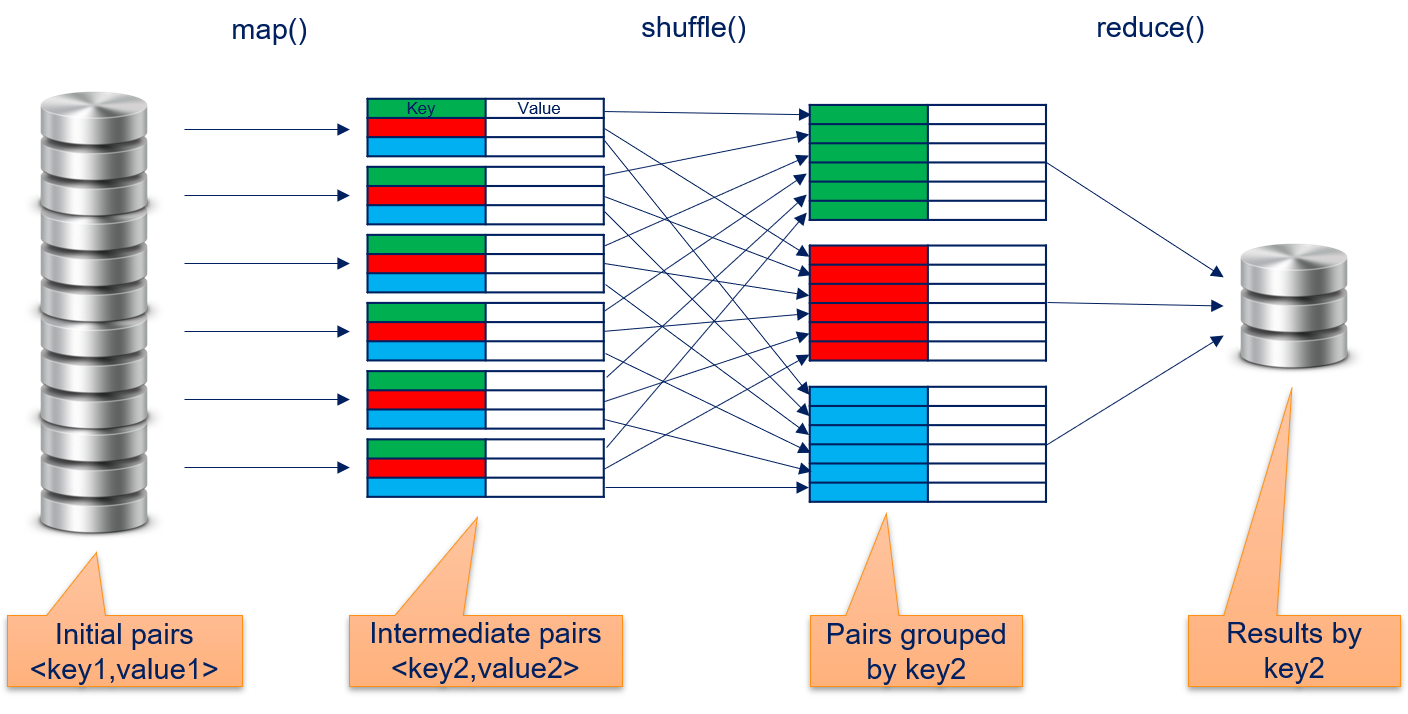
map()
The map function gets initial key-value pairs. These are, e.g., read from the distributed storage or the result of a prior computation using MapReduce. The map function than performs a computation on a single key-value pair and stores the results in new key-value pairs. Because the map function only gets a single key-value pair as input, data parallelization is trivial: theoretically, the map function could run in parallel for all key-value pairs without any problem. The map function is defined as
$$map(f_{map}, <key1, value1>) \rightarrow list(<key2, value2>)$$where $f_{map}$ is a user-defined function (UDF) defined by the user of the MapReduce framework. The UDF defines the computation, i.e., how the input key-value pair is transformed into the list of output key-value pairs. Depending on the UDF $f_{map}$, the input keys and output keys could be same or different. While the general concept of MapReduce does not have any restrictions on the type and values of the keys, implementations of MapReduce may restrict this. For example, in the initial implementation of MapReduce by Google, all keys and values were strings and users of MapReduce were expected to convert the types within the map and reduce functions, if required.
shuffle()
The key-value pairs computed by the map function are organized by the shuffle function, such that the data is grouped by the key. These are then organized by the shuffle and grouped by their keys. Thus, we have
$$shuffle(list<key2, value2>) \rightarrow list(<key2, list(value2)>),$$i.e., a list of values per key. Often, these data from shuffle is sorted by key, because this can sometimes improve the efficiency of subsequent tasks. The shuffling is often invisible to the user performed in the background by the MapReduce framework.
reduce()
The reduce function operates on all values for a given key and aggregates the data into a single result per key. The reduce function is defined as
$$reduce(f_{reduce}, <key2, list(value2)>) \rightarrow value3$$where $f_{reduce}$ is a UDF. The UDF $f_{reduce}$ performs the reduction to a single value for one key and gets as input the key and the related list of values. Similar as for the map function, there is no restriction on the type or the values that are generated. Depending on the task, the output could, e.g., be key value pairs, integers, or textual data.
Word Count with MapReduce
The concept of MapReduce is relatively abstract, unless you are used to functional programming. How MapReduce works becomes clearer with an example. The "Hello World" of MapReduce is the word count, i.e., using MapReduce to count how often each word occurs in a text. This example is both practically relevant, e.g., to create a bag-of-words, and well suited to demonstrate how MapReduce works.
We use the following text as example:
What is your name?
The name is Bond, James Bond.Our data is stored in a text file with one line per sentence. Our initial keys are the line numbers, our initial values the text in the lines. Thus, we start with these key-value pairs.
<line1, "What is your name?">
<line2, "The name is Bond, James Bond.">The map function is defined such that it emits the pair <word, 1> for each word in the input. When we apply this to our input, we get the following list of key-value pairs.
<"what", 1>
<"is", 1>
<"your", 1>
<"name", 1>
<"the", 1>
<"name", 1>
<"is", 1>
<"bond", 1>
<"james", 1>
<"bond", 1>The shuffle then groups the values by their keys, such that all values for the same key are in a list.
<"bond", list(1, 1)>
<"is", list(1, 1)>
<"james", list(1)>
<"name", list(1, 1)>
<"the", list(1)>
<"what", list(1)>
<"your", list(1)>As reduce function, we output one line for each key. The lines contain the current key and the sum of the values of that key.
bond 2
is 2
james 1
name 2
the 1
what 1
your 1Parallelization
The design of MapReduce enables parallelization for every step of the computational process. The input can be read in chunks to parallelize the creation of the initial key-value pairs. For example, we could have multiple text files, each with 1000 lines that could be processed in parallel. The parallelism is limited by the throughput of the storage and makes more sense, if the data is distributed across multiple physical machines.
map() can be applied to each key-value pair independently and the potential for parallelism is only limited by the amount of data.
shuffle() can start as soon as the first key-value pair is processed by the map function. This reduces the waiting times, such that the shuffling is often finished directly after the last computations for map are finished.
reduce() can run in parallel for different keys. Thus, the parallelism is only limited by the number of unique keys created by map(). Moreover, reduce() can already start, once all results for a key are available. This is where sorting by shuffle can help. If the results passed to reduce() are sorted, reduce can start processing for a key, once it sees results for the next key.
Apache Hadoop
Apache Hadoop is an open source implementation of MapReduce. For many years, Hadoop was the standard solution for any MapReduce application and Hadoop is still relevant for many applications. All major cloud providers offer Hadoop clusters in their portfolio. Hadoop 2.0 implements MapReduce in an architecture with three layers.
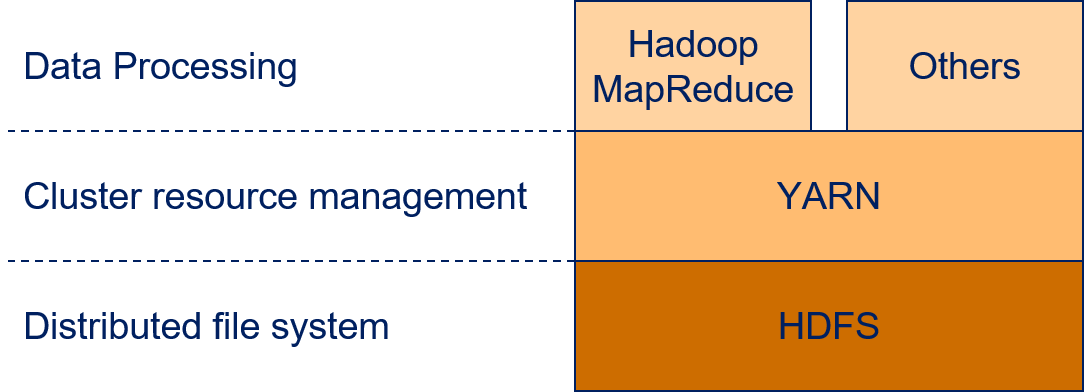
The lowest layer is the Hadoop Distributed File System (HDFS) that is in charge of the data management. Yet Another Resource Negotiator (YARN) is running on top of the file system. YARN manages the use of computational resources within a Hadoop cluster. Applications for data processing that want to use the Hadoop cluster are running on top of YARN. For example, such applications can be written with the Hadoop implementation of MapReduce. However, due to the success of the HDFS and YARN, there are also other technologies that can be used for data processing, e.g., Apache Spark, which we discuss below.
HDFS
The HDFS is the core of Hadoop. All data that should be analyzed is stored in the HDFS. HDFS was designed with the goal to enable Big Data processing, which is why HDFS behave quite differently from other file systems that we regularly use like NTFS, ext3, or xfs.
- HDFS favors high throughput at the cost of low latency. This means that loading and storing large amounts of data is fast, but you may have to wait some time before the operation starts.
- HDFS supports extremely large files. The file size is only limited by the amount of distributed storage, i.e., files can be large than the storage available at a single node.
- HDFS is designed to support data local computations and minimize the data that needs to be send around in a cluster for file operations.
- Since outages of single nodes in a large compute cluster is not a rare event, but rather a part of the daily work, HDFS is designed to be resilient against hardware failures, such that there is no loss of data and no interruption of service.
In principle, HDFS uses a master/worker paradigm with a NameNode that manages DataNodes.
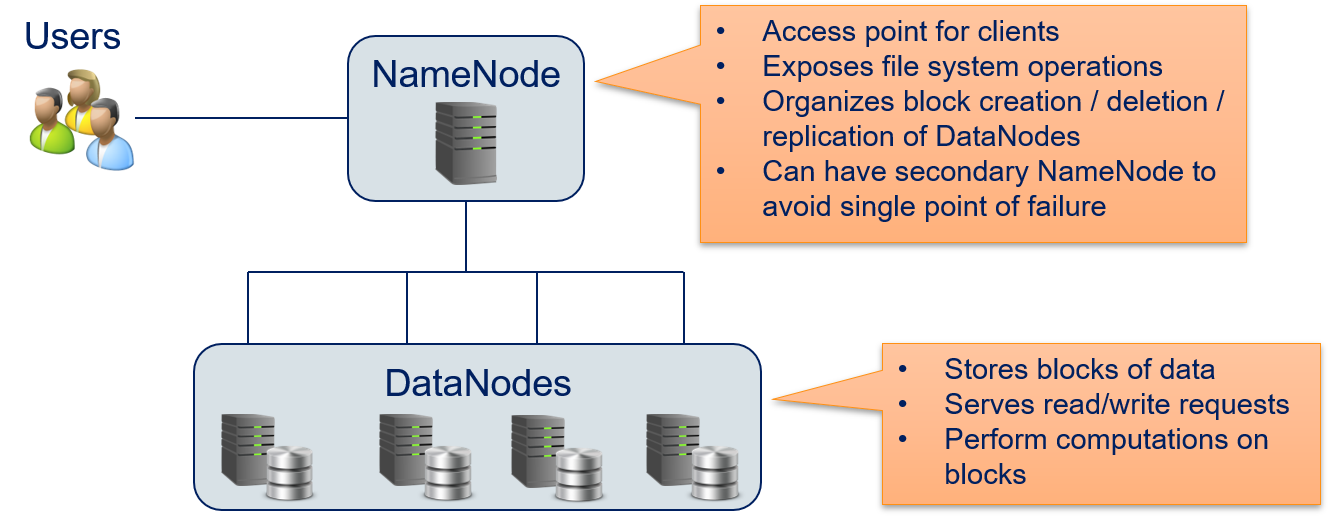
Clients access the HDFS via the NameNode. All file system operations, such as the creating, deletion, copying of a file is performed by requesting this at the NameNode. Whenever a file is created, it is split into smaller blocks. The NameNode organizes the creation, deletion, and replication of blocks on DataNodes. Replication means that each block is not just stored on a single DataNode, but on multiple DataNodes. This ensures that no data is lost, if a data node is lost. To avoid that the HDFS is not available if the NameNode crashes, there can also be a secondary NameNode. This avoids that the NameNode is a single point of failure. If there is a problem with the primary NameNode, the secondary NameNode can take over without loss of service.
Another important aspect of the HDFS is that while users access the HDFS via the NameNode, the actual data is never sent via the NameNode to the DataNodes, but directly from the users to the DataNodes. The following figure shows how a file in HDFS is created by a user.
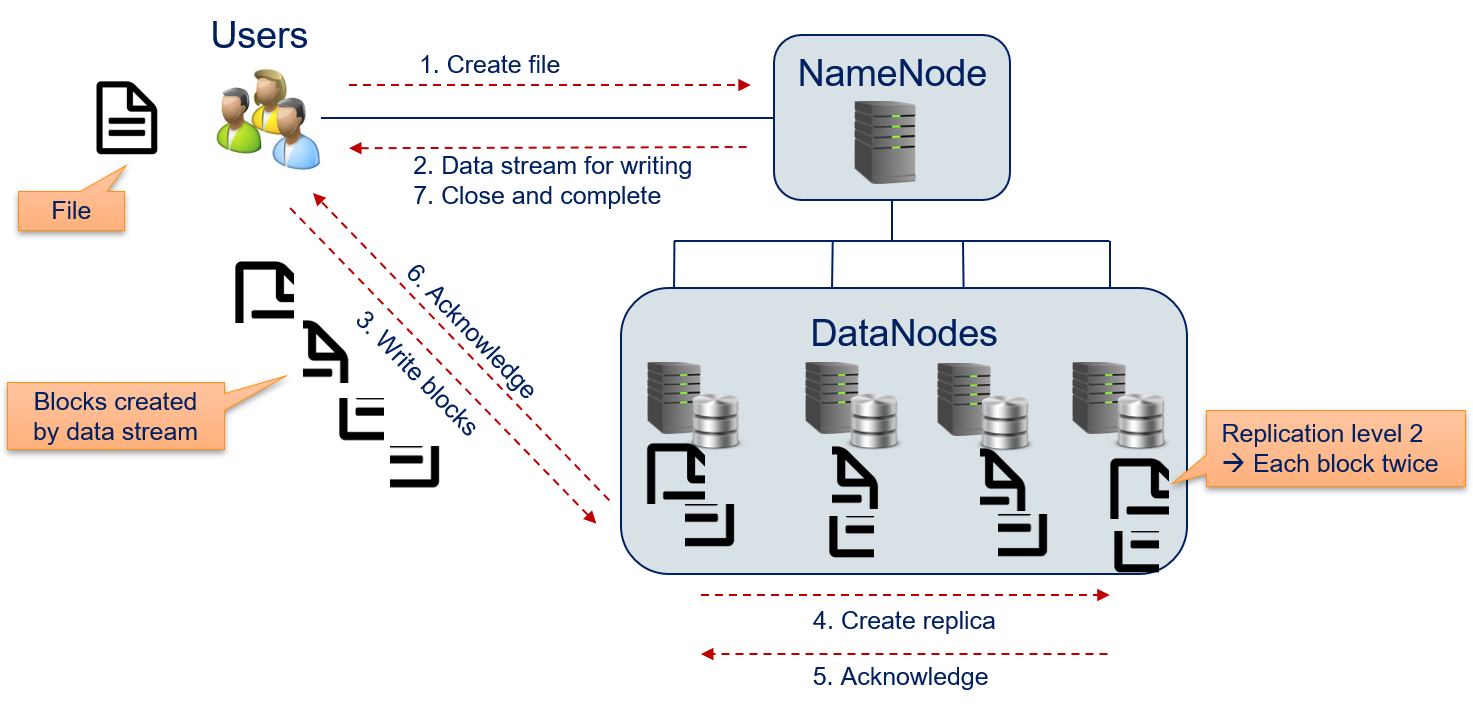
- The user contacts the NameNode with the request to create a new file.
- The name node responds with a data stream that can be used for writing the file. From the user's perspective, this is a normal file stream that would be used for local data access (e.g.,
FileInputStreamin Java,ifstreamin C++,openin Python). - The user writes the contents of the file to the file stream. The NameNode configured the file stream with the information how the blocks should look like and where the data should be sent. The data is directly sent block-wise to one of the DataNodes.
- The DataNode that receives the block does not necessarily store the block itself. Instead, the block may be forwarded to other DataNodes for storage. Each block is stored at different nodes and the number of these nodes is defined by the replication level. Moreover, the HDFS ensures that blocks are evenly distributed among the data nodes, i.e., a DataNode only stores multiple blocks of a file, if the block cannot be stored at another DataNode. Ideally, all DataNodes store the same number of blocks of a file.
- When a DataNode stores a block, this is acknowledged to the DataNode that receives the data from the user.
- Once the DataNode received acknowledgements for all replications of a block, the DataNode acknowledges to the user that the block is stored. The user can then start sending the data for the next block (go to step 3), until all blocks are written. The user does not observe this behavior directly, because this is automatically handled by the file stream.
- The user informs the NameNode that the writing finished and closes the file stream.
YARN
The second core component of Hadoop is YARN, which is manager for computational resources that is designed to enable distributed Big Data computations with data stored in the HDFS. Same as the HDFS, YARN has a master/worker paradigm.
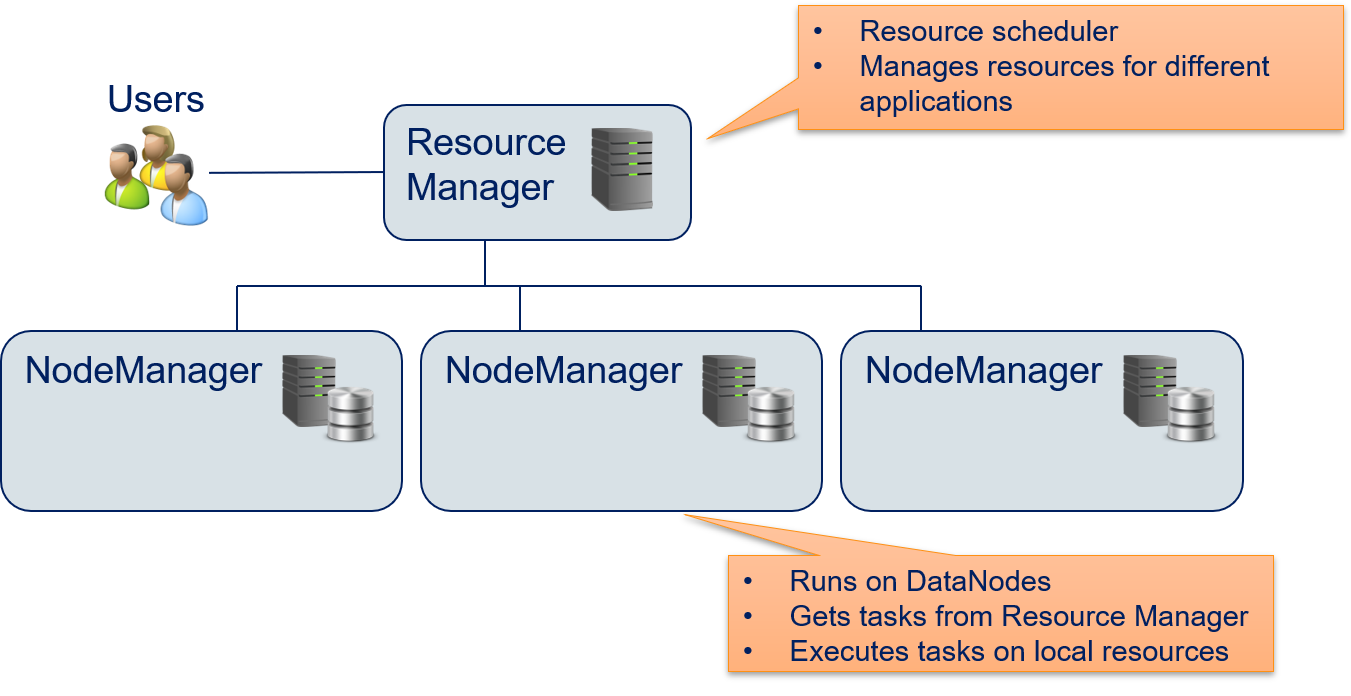
The Resource Manager is the scheduler that provides resources for applications to enable the computations. The NodeManagers are applications running on the DataNodes. The NodeManager execute tasks on the local resources. This way, each DataNode can serve as compute node. The computational tasks are allocated such that they are executed by the NodeManagers running on the DataNodes where the required data is stored. Thus, the combination of DataNodes and NodeManagers running on the same physical machine and the Resource Manager that is aware where the data is stored in the HDFS enables data local computations. The computational tasks are, e.g., executed using MapReduce. However, YARN can in principle run any kind of computational task on the NodeManagers and is not limited to MapReduce.
The Resource Manager should schedule the computational task such that the resources (CPU cores, memory) are spent efficiently. This means that NodeManagers should ideally only execute one task at a time, to prevent overutilization. Underutilization should also be avoided: if there are jobs waiting for their execution and at the same time, there are idle NodeManagers that could conduct the jobs, the jobs should get these resources. This means that the Resource Manager should must be able to provide resources to multiple jobs, possibly of multiple users, at the same time.
The following figure shows how YARN executes application in a distributed manner and schedules resources.
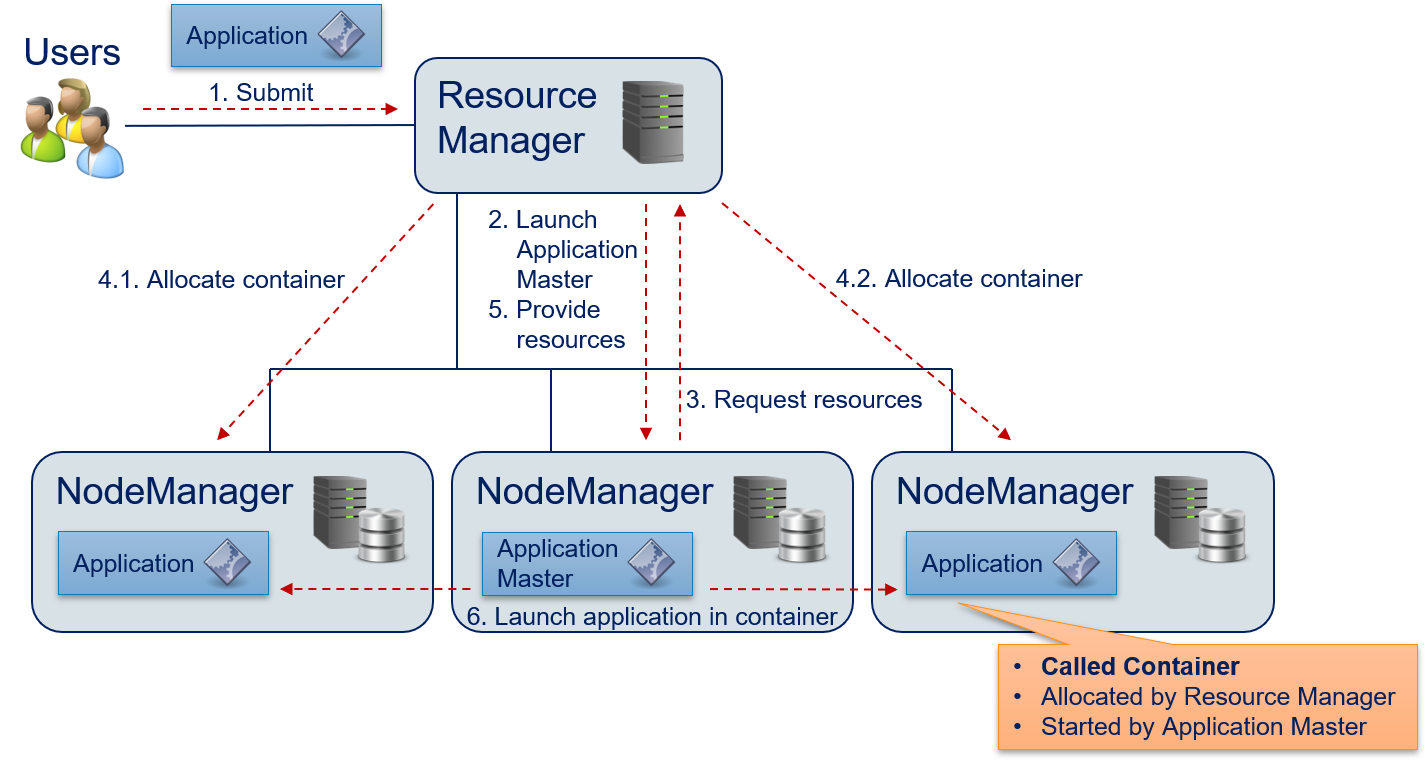
- The user submits an application to the Resource Manager. The Resource Manager queues this application until there are sufficient capacities in the compute cluster to start the execution.
- The Resource Manager allocates a container on one of the NodeManagers and launches the application master. The application master is not the application itself, but rather a generic program that knows how to execute the application, e.g., which resources are required and which tasks must be executed.
- The application master requests the resources required for computations from the Resource Manager.
- The node manager allocates the required containers. In the example, these are two containers running on the NodeManagers on the left and right side.
- The Resource Manager informs the application master that the required resources are allocated. This information includes the data required to access the containers.
- The application master executes (parts of) the application in the containers. The application managers may configure the environment through environment variables. The applications are then using local resources of the host where the NodeManager is running, e.g., binary or data from the HDFS.
Once the application is finished, all containers are destroyed. The results only accessible via the HDFS. The resource requests (step 3) may use the following information to specify the required resources:
- The required number of containers.
- CPU cores and memory that are required per container.
- The priority of the request. This priority is local to the application and not global. This means that the priority only influences which of the resources a specific application requests it gets first. A higher priority does not give any advantages in scheduling with respect to other applications that are also requesting resources from the Resource Manager.
- It is also possibly to directly specify the name of the desired computational resources. This could either be a specific host of NameNode, but also a more generic property of the topography of the compute cluster, e.g., in which rack the host should be located.
MapReduce with Hadoop
Hadoop provides a MapReduce implementation that uses YARN for the execution. In such a MapReduce application, users define sequences of map()/reduce() tasks to solve their problem. The execution is driven by the MRAppMaster Java application. This application specifies a YARN application master that manages the execution of tasks, in this case of the map() and reduce() tasks. Users specify the MapReduce applications through a Java application. Hadoop also has a streaming mode for job execution, which we discuss below.
The tasks of MapReduce applications are specified through subclassing. Subclasses of the Mapper class define map() functions, subclasses of the Reducer class define reduce(). The code below specifies the map() function for the word count example. Please note that we omit all boilerplate code from the code samples, e.g., import statements. The complete example can be fount in the official Hadoop documentation.
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
// text into tokens
StringTokenizer itr = new StringTokenizer(value.toString().toLowerCase());
while (its.hasMoreTokens()) {
// add an output pair <word, 1> for each token
word.set(itr.nextToken());
context.write(word, one);
}
}
}
The TokenizerMapper class extends to generic class Mapper with four parameters of types Object, Text, Text, and IntWritable. The first two parameters specify the types of the key and value of the input key-value pairs of the map() function, which means we have keys of type Object and values of type Text. the last two parameters specify the type of output key-value pairs, which means we have keys of type Text with values of type IntWritable. Text and IntWritable are data types provided by Hadoop that are similar to their Java counterparts String and Integer. The key differences between the Hadoop types and the standard Java types are that of the Hadoop types are mutable, i.e., the values of objects can be modified, and the Hadoop types are optimized for serialization to improve the efficiency of exchanging key-value pairs between different map() and reduce() tasks.
The class has two attributes one and word, which are used to generate the output keys and values. These advantage of having these as attributes is that they are not initialized with every call of map(), which improves the efficiency. Finally, we have map() function, defines how the input key values are mapped to the output pairs. In addition to the input key and value, map() gets the context. This context specifies the Hadoop execution environment and contains, e.g., values of environment variables. Moreover, the context receives the output of the map() function through the context.write() method. Thus, the map() function does not return values, but continuously writes results for which the computation finished to the context. The context contains the shuffle() function and can immediately start shuffling the output key-value pair, once it was written. Thus, shuffling can already start before the first map() function finished.
The code below shows the reduce() function for the word count.
public static class IntSumReader extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context
) throws IOException, InterruptedException {
// calculate sum of word counts
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
// write result
context.write(key, result);
}
}
The IntSumReader class extends the generic class Reducer. Same as for the TokenizerMapper, the parameters describe the types of the input, respectively out, the attribute result is used for efficiency, and the result is written to the context. The only notable difference between the classes is that the reduce function gets an Iterable of values and not a single value, i.e., all values for the key.
Finally, we need to use these classes in a MapReduce application. The code for the application is below.
public class WordCount {
public static void main(String[] args) throws Exception {
// Hadoop configuration
Configuration conf = new Configuration();
// Create a Job with the name "word count"
Job job = Job.getInstance(conf, "word count");
job.setJahrByClass(WordCount.class);
// set mapper, reducer, and output types
job.setMapperClass(TokenizerMapper.class);
job.setReduczer(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// specify input and output files
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// run job and wait for completion
job.waitForCompletion(true);
}
}
The application is a normal Java application with a main method and the code is more or less self-explanatory. First, we create the configuration of Hadoop application. This object contains, e.g., the context and MapReduce tasks. We use the configuration to create a new MapReduce job. Then, we configure the Job. We define in which class it is defined, which classes are used for the map() and reduce() steps, and what the types of the outputs are. Finally, we specify where the input data come from and where the output should be written, based on the command line arguments of the application. The final line starts the job and blocks further execution, until the job is finished, i.e., all map() and reduce() functions finished their work and the results are available in the file system.
Word Count with Hadoop
Since it is not intuitive how Hadoop/YARN orchestrate the execution of a MapReduce application, we now demonstrate this in detail step by step using the word count example.
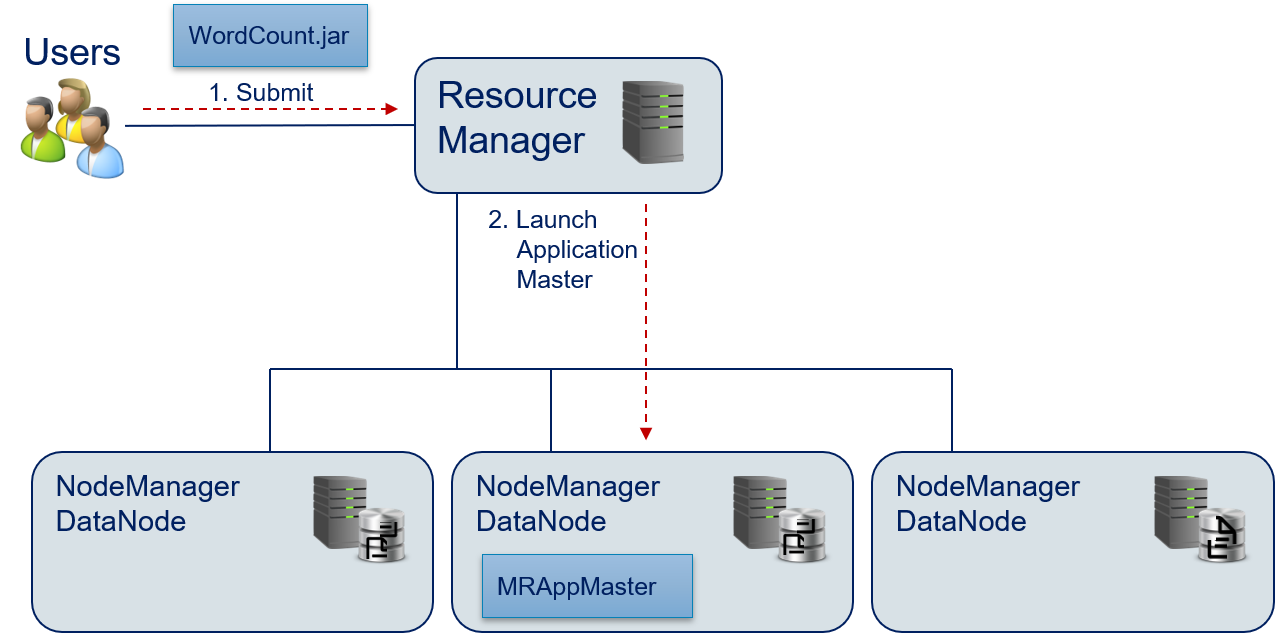
- The user builds the jar-Archive of the MapReduce application and submits this application to the Resource Manager.
- The Resource Manager launches the MRAppMaster application master to orchestrate the execution of the WordCount.jar.
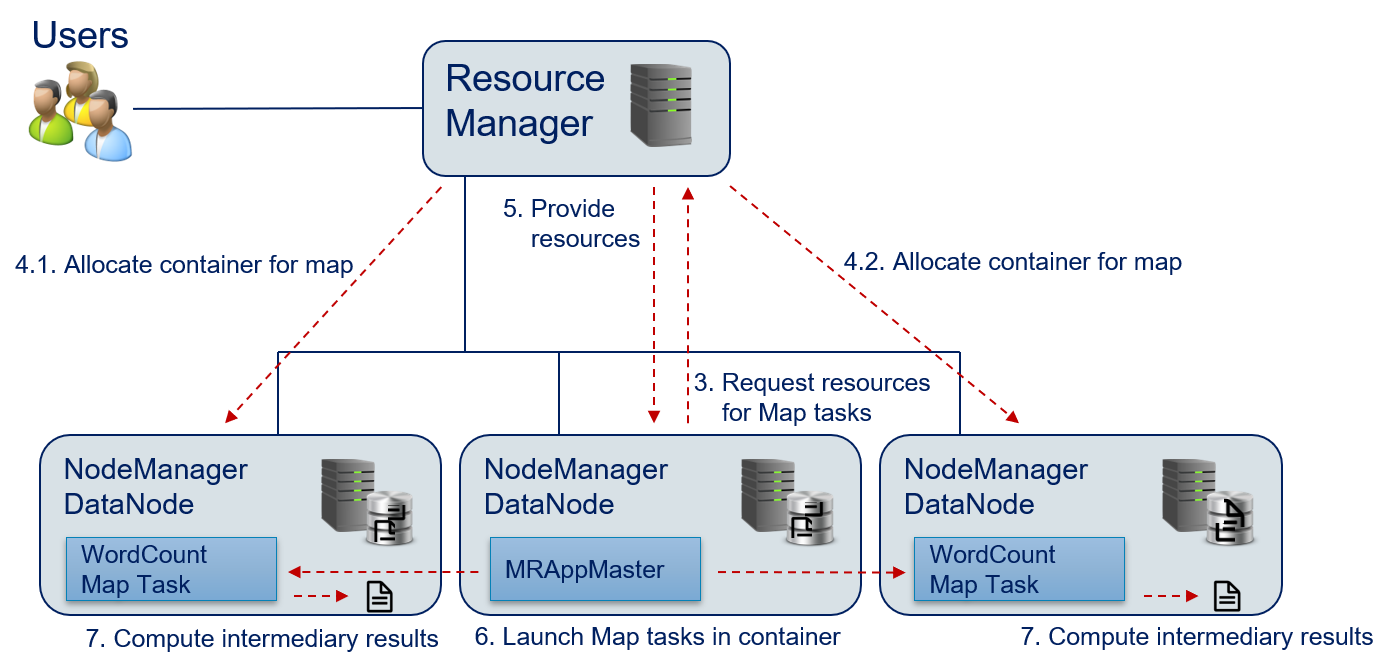
- The MRAppMaster evaluates the configuration of the Hadoop application in the WordCount.jar and finds one jobs that consists of a map() and a reduce() function. The MRAppMaster requests the required resources for the map() function from the Resource Manager.
- The Resource Manager provides the required compute resources. The resources are allocated on the DataNodes, where blocks of the input data are stored, such that this data does not need to be transfered over the network.
- The Resource Manager sends the information where the map() task can be executed to the MRAppMaster.
- The MRAppMaster launches the map() function in the containers that were allocated. The required data is directly read from the HDFS.
- The map() function is executed and the results are written by to intermediary results files in the HDFS.
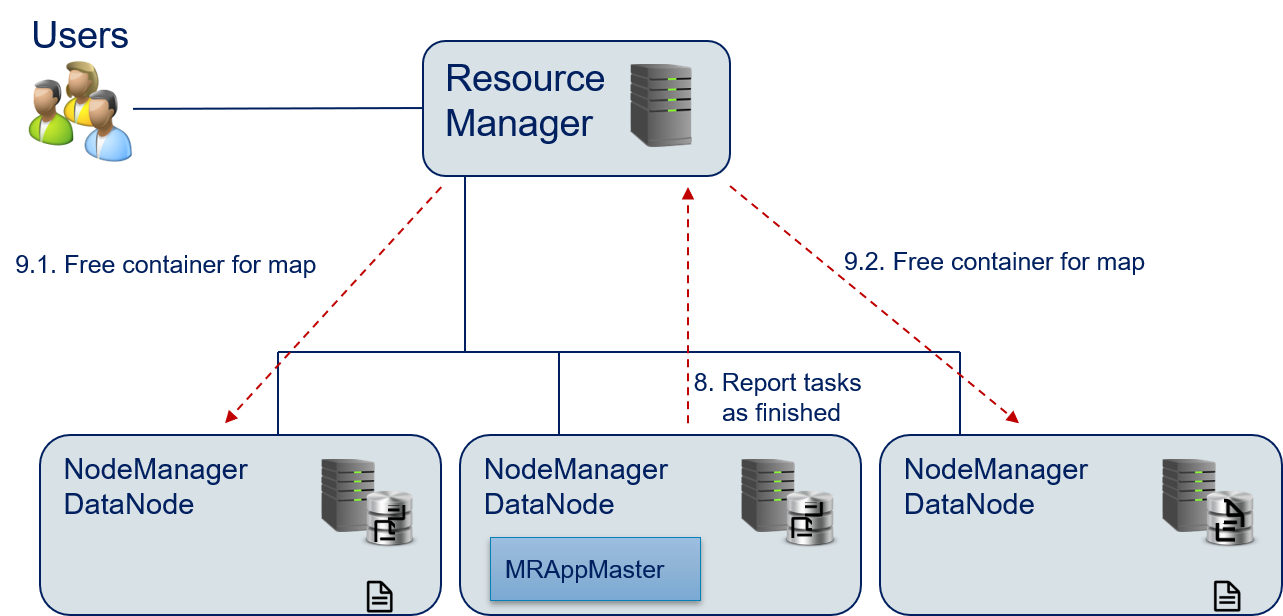
- The MRAppMaster reports that the task is finished and the resources are no longer required to the Resource Manager.
- The Resource Manager destroys the containers for the map() functions to free the resources.
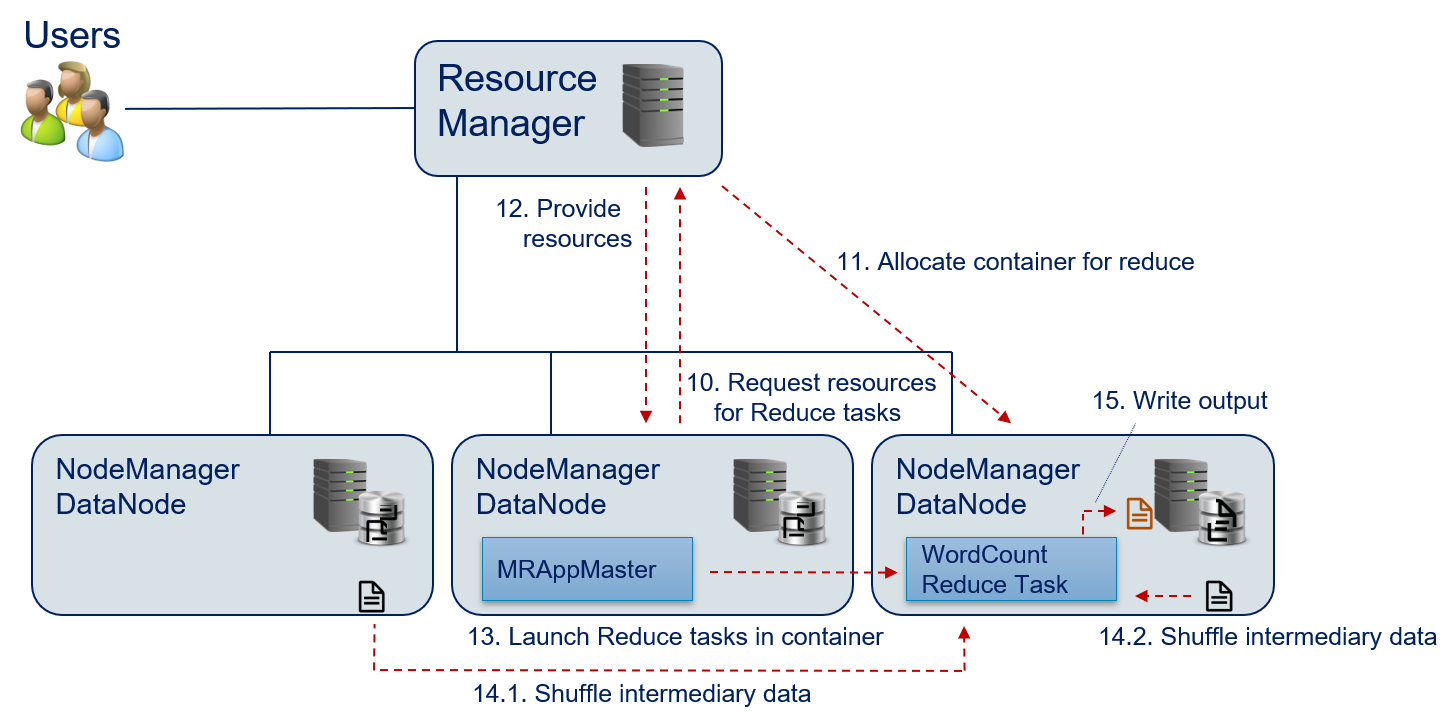
- The MRAppMaster requests the required resources for the reduce() function. This requires only a single container, because the results are aggregated.
- The Resource Manager allocates the required resources.
- The Resource Manager sends the information where the map() task can be executed to the MRAppMaster.
- The MRAppMaster launches the reduce() function in the allocated container.
- The MRAppMaster triggers the shuffle() function to organize and group the intermediary data from the different nodes and provide the data to the reduce() function.
- The reduce() function writes the output to the HDFS.
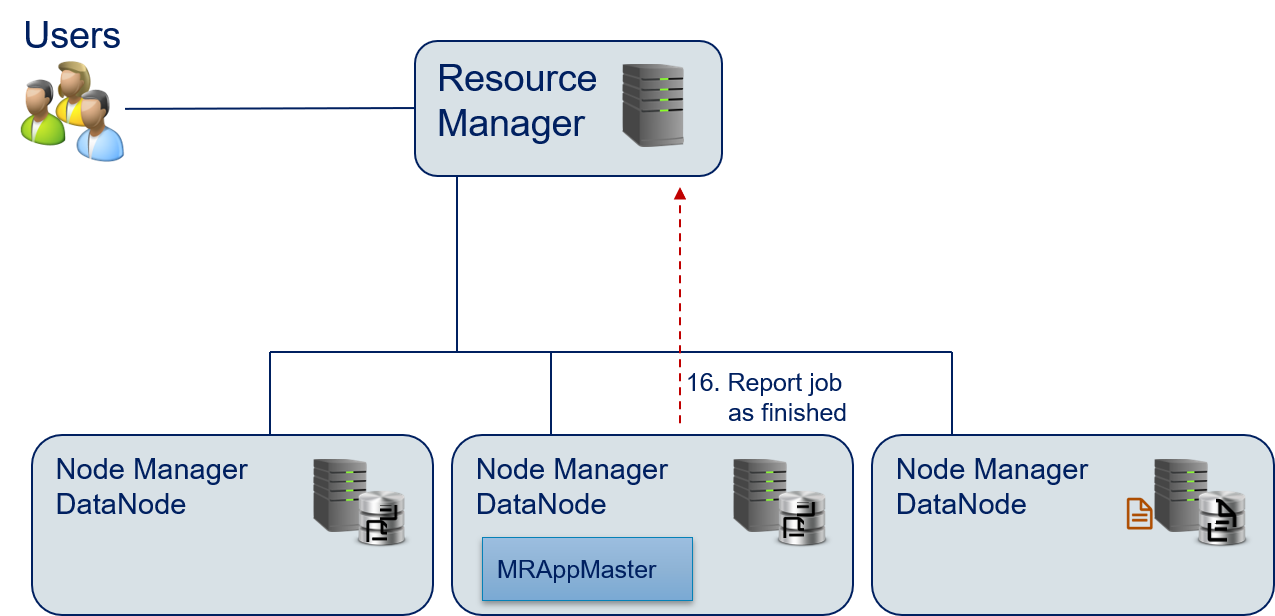
- The MRAppMaster reports that the task and the execution of the application are finished to the Resource Manager.
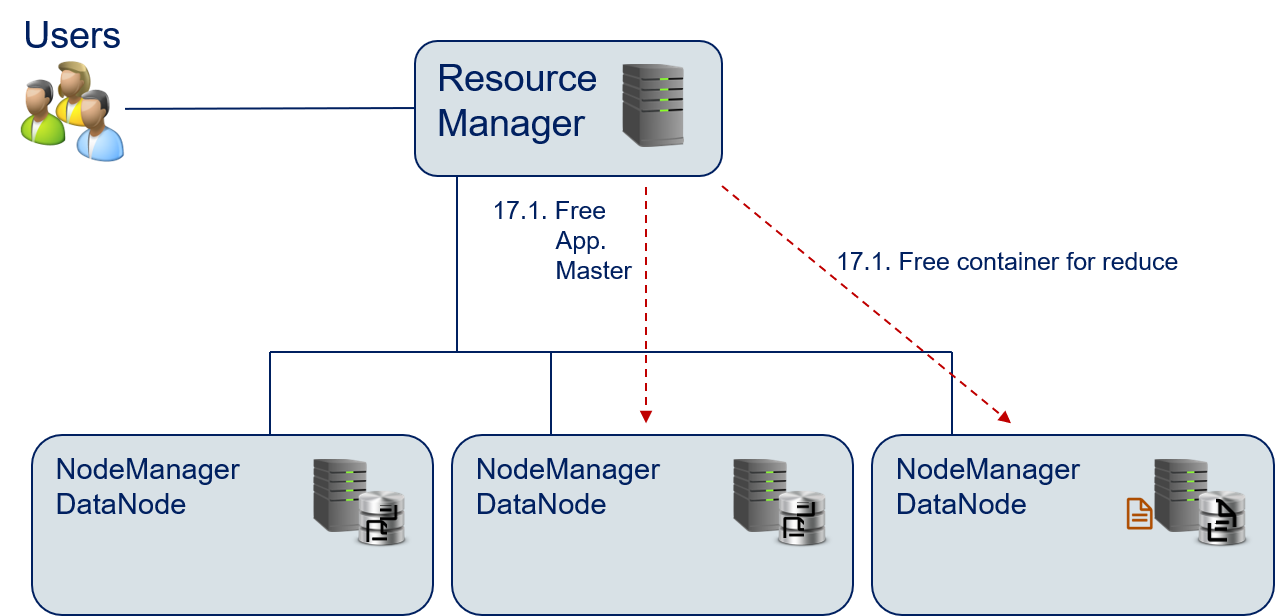
- The Resource Manager destroys the containers of the reduce() function and the MRAppMaster to free the resources.
Streaming Mode
Hadoop also provides a Java Application that can be used to Hadoop in the streaming mode. In the streaming mode, the standard input and standard output are used, similar to Linux pipes. The data from the HDFS is read and forwarded to an arbitrary application that processes the data from the standard input. The results of the computation are written to the standard output. For example, a python script for the map() function of the word count would look like this.
#!/usr/bin/env python
"""mapper.py"""
import sys
# read from standard input
for line in sys.stdin:
# split line into words
words = line.strip().split()
# create output pairs
for word in words:
# print output pairs to standard output
# key and value are separated by tab (standard for Hadoop)
print('%s\t%s' % (word, 1))
Similarly, the reduce() function would also use the standard input and output.
#!/usr/bin/env python
"""reducer.py"""
from operator import itemgetter
import sys
# init current word and counter as not existing
current_word = None
current_count = 0
word = None
# read from standard input
for line in sys.stdin:
# read output from mapper.py
word, count = line.strip().split('\t', 1)
count = int(count)
# Hadoop shuffle sorts by key
# -> all values with same key are next to each other
if current_word==word:
current_count += count
else:
if current_word:
# write result to standard output
print('%s\t%s' % (current_word, current_count))
# reset counter and update current word
current_count = count
word = word
# output for last word
if current_word==word:
print('%s\t%s' % (current_word, current_count))
The streaming mode can be used with any programming language, as long as inputs are read from the standard input and outputs are written to the standard output stream. Technically, the streaming mode is just a Hadoop MapReduce implementation that is bundled as a jar-Archive and can be used. For example, the following command could be used to run the word count.
hadoop jar hadoop-streaming.jar \
- input myInputDirs \
- output my OutputDir \
- mapper mapper.py \
- reducer reducer.py \
- file mapper.py \
- file reducer.pyThe hadoop-streaming.jar is a normal MapReduce implementation of MapReduce in Java, as we have it explained above. The map() function of this jar calls the mapper.py within its map() function and the reducer.py within its reduce function() and communicates with the python scripts via the standard input/output. The input and output parameters define where the data is read from and where the results will be written to in the HDFS. The final two parameters are required, to make the Python scripts available on the compute nodes.
Additional Components
In addition to the core components we have shown above, there are several other components, that we do not discuss in detail, but want to mention regardless. We briefly want to discuss two of these additional components.
Combiner functions are similar to reduce() function, but are running locally on each DataNode and are executed before shuffling the data to another node. In many use cases, the combiners are identical to reduce(). In the word count example, we can apply reduce() multiple times in a row without problems, since the reducer function creates the sum of the values of the keys. Without a combiner, these values will always be exactly one. With a combiner, we would create a word count locally on each DataNode, then shuffle the word counts of the nodes to reduce() function, that would create the total word count from the word counts on each DataNode. Combiners can, therefore, reduce the traffic between nodes by aggregating results prior to the reduce() function. For example, we would shuffle one pair <bond, 2> instead of two pairs <bond, 1> to the reducer, thereby cutting the traffic in half. The larger the amount of data that is handled locally at each node in the Hadoop cluster, the larger the potential for reducing the traffic with a combiner. The requirement for chaining functions this way is that the functions are idempotent.
The MapReduce Job History Server is another user-facing component of a Hadoop deployment. Users of a Hadoop cluster can access the Job History Server to access information about submitted Hadoop application. This information includes log files of the job execution, start and end times, as well as the state of the job, e.g., whether it it pending, running, finished, or failing.
Limitations
Hadoop has two major limitations. The first is that if an algorithm requires multiple map() and/or reduce() functions, their order of execution must be manually specified through the creation of Job objects and through the definition of their dependencies. This means that we cannot just add multiple map() or reduce() jobs in a specific order to a Job object, but instead have to define multiple Job objects, specify which Job object needs to wait for which other objects, to which Job object the output of a Job object should possibly be forwarded as input, etc. This manual modeling of dependencies is error prone and mistakes are hard to spot.
Related to this limitation is that the jobs always have to write their intermediary results to the HDFS. While this is not a problem is the data only needs to be read and processed once, this is severe overhead if multiple computations on the same data are performed, because the results are not kept in-memory. Thus, iterative algorithms are not very efficient with Hadoop.
Apache Spark
Apache Spark is another framework for working with Big Data that was created with the motivation to overcome the limitations of Hadoop: in memory data analysis, such that intermediary results do not have to be written to the HDFS and the convenient support for complex algorithms with many map() and reduce() functions.
Components
The first difference of Spark in comparison to Hadoop is that Spark contains a powerful software stack for data analysis, while Hadoop only provides basic functionality, which is often used by other software to provide these functions. Apache Spark consists of core components that are responsible for the Big Data processing. On top of these functionality, Spark provides libraries that simplify the definition of data analysis tasks.
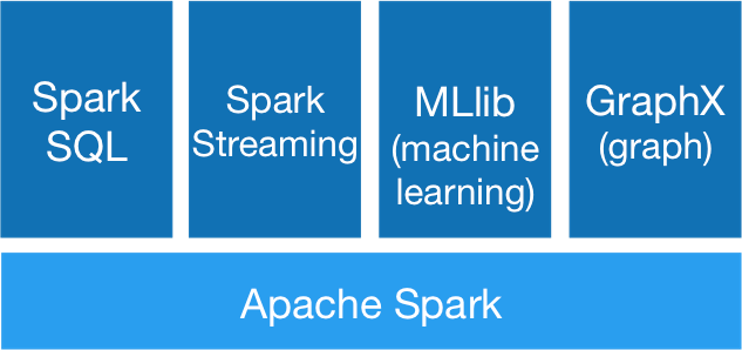
Spark SQL suppers SQL-like queries to the data that is used within analysis. Because SQL is such a widespread language for working with data, this allows users to load and manipulate data with Apache Spark without a steep learning curve. Spark Streaming enables the live processing of streaming data. This way, Spark can handle continuously incoming data, which is another limitation of Hadoop. With the MLlib and GraphX, Spark also contains two libraries for data analysis. MLlib provides implementations for many of the algorithms we saw in the last chapters. GraphX is for processing of graph data, e.g., social networks.
Data Structures
The data structures of Spark are designed for in-memory data processing, which is in contrast to the HDFS approach by Hadoop where file operations are used. At the core, data is contained in Resilient Distributed Datasets (RDDs). These data structures provide an abstraction layer for data operations, independent of the actual type of the data. The RDDs organize data in immutable partitions, such that all elements in a RDD can be processed in parallel. Thus, the RDDs are similar to the key-value pairs of Hadoops MapReduce. Consequently, Spark allows the definition of map() and reduce() functions on RDDs, given that the data within the RDD are key-value pairs. However, Spark goes beyond the capabilities of Hadoop, because RDDs can also contain data that are not key-value pairs, filtering of RDDs is supported and, in general, any user-defined function can be applied to the data within an RDD. Additionally, the RDDs can be persisted to the storage, if requested.
Since Spark 2.0, users of Apache Spark do not have to work with RDDs anymore, but can also use data frames, similar to the data frames we know from pandas. This data frame API is rightly coupled with the Spark SQL components, which is the primary way for creating the data frames. The support for data frames is another reason why getting started with Spark is often simpler than with other Big Data frameworks.
Infrastructure
While Spark contains all components to create a compute cluster, this is not the normal way in which Spark is used. Instead, Spark is usually used together with one of the many compatible technologies. For example, Spark is fully compatible with YARN and HDFS, i.e., data stored in Hadoop clusters can also be analyzed with Apache Spark. Spark can also be used with many other technologies, e.g., EC2 clouds or Kubernetes for computation or databases like Cassandra, HBase, or MongoDB for storage. Thus, analysis designed with Apache Spark are not locked into a specific framework, which is another notable difference to Hadoop.
Word Count with Spark
While Spark itself is written in Scala, Spark applications can also be written in Java, Python (PySpark), and R (SparkR). Users do not have to define the dependencies between different tasks manually. Instead, Spark assumes that the order in which the tasks are defined is the order in which they should be executed. If tasks are using different data, they can be executed in parallel, if a task requires data from a previously defined task, this data is automatically shuffled to the task and the execution only starts when the data is available. Due to this, the source code for Spark jobs contains less boilerplate code for defining formats than that of Hadoop applications. For example, with Apache Spark, the word count my look like this.
# sc is the SparkContext, which is similar to the Configuration of Hadoop
text_file = sc.textFile("hdfs://data.txt")
# flatMap can input map the input to multiple outputs
# map maps each input to exactly one output
# reduce by key is the same as reduce in Hadoop
counts = text_file.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
counts.saveAsTextFile("hdfs://wc.txt")
Thus, complex tasks can be implemented easier with a framework like Spark.
Note:
Python
lambdafunctions are anonymous functions that can expressed in one line. For example,lambda a, b: a+bwould be the same as defining and calling a functiondef fun(a, b): return a+b
Beyond Hadoop and Spark
With Hadoop and Spark we present to popular technologies for Big Data analysis. However, due to importance of Big Data in the last decade, there are also many other important technologies, e.g., databases that are optimized for Big Data, alternatives for Stream processing of data, or tools for the management of compute clusters. There are whole ecosystems around Hadoop, Spark, and other technologies, that are often to some degree compatible with each other. This tool landscape is still evolving and constantly changing, even though some core technologies, like Hadoop or Spark for computations, or databases like Cassandra have now been important parts of the market for many years. Regardless, a complete discussion of tools is out of our scope.
A strong aspect of Big Data is that many of the state-of-the-art technologies are open source, meaning that often there are no licensing costs associated with using the software. Regardless, using these tools is still often not cheap, because the resources for running Big Data applications are expensive.