
With this exercise, you can learn more about classification. You can try out the algorithms on a data set and compare the performance of the different classifiers with different performance metrics.
Please note that the biggest challenge of this exercise is to select good hyper parameters of the algorithms, e.g., tree depths, activation functions, etc. The performance of the algorithms depends on this. In the bonus task, you can see that this can quickly consume huge amounts of computational capacity.
Libraries and Data
Your task in this exercise is pretty straight forward: apply different classification algorithms to a data set, evaluate the results, and determine the best algorithm. You can find everything you need in sklearn. We use data about dominant types of trees in forests in this exercise.
We start by loading the data an importing the libraries we require. We also print the description of the data.
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_covtype
from sklearn.metrics import precision_recall_fscore_support,matthews_corrcoef
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LogisticRegression
forests = fetch_covtype()
X = forests.data
Y = forests.target
print(forests.DESCR)
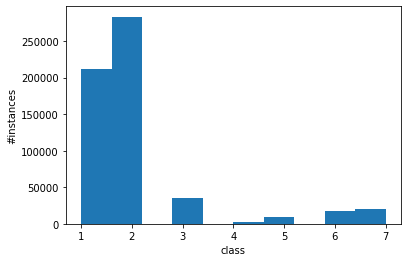
We now take a rudimentary look at the data. Most importantly, we check if there is class level imbalance or if each class is represented the same in the available data.
plt.figure()
plt.hist(Y)
plt.ylabel('#instances')
plt.xlabel('class')
plt.show()
Training and test data
Before you can start building classifiers, you need to separate the data into training and test data. Because the data is quite large, please use 5% of the data for training, and 95% of the data for testing. Because you are selecting such a small subset, it could easily happen that not all classes are represented the same way in the training and in the test data. Use stratified sampling to avoid this.
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.95, random_state=42, stratify=Y)
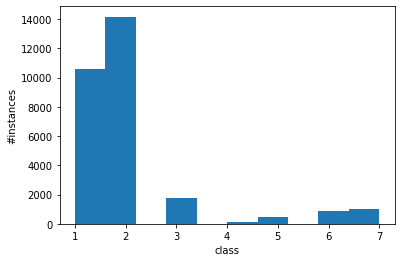
We check the distribution of the class labels in the training data to ensure that the stratification had the desired effect.
plt.figure()
plt.hist(Y_train)
plt.ylabel('#instances')
plt.xlabel('class')
plt.show()
Train, Test, Evaluate
Now that training and test data are available, you can try out the classifiers from Chapter 7. You will notice that some classifiers may require a long amount of time for training and may, therefore, not be suitable for the analysis of this data set.
Try to find a classifier that works well with the data. On this data, this means two things:
- Training and prediction in an acceptable amount of time. Use "less than 10 minutes" as definition for acceptable on this exercise sheet.
- Good prediction performance as measured with MCC, recall, precision, and F-Measure.
The different classifiers have different parameters, also known as hyper parameters, e.g., the depth of a tree, or the number of trees used by a random forest. Try to find good parameters to improve the results.
We train a $k$-Nearest Neighbors Classifier with $k=3, 5, 10$, Decision Trees with maximal depths 5, 10, and 20, Random Forests with 1000 trees in the ensemble that have maximal depth of 3 and 5, a Logistic Regression classifier, a Gaussian Naive Bayes, and MLPs with three hidden layers with 100 neurons with RelU and tanh as activation functions. Thus, we test some parameter combinations that affect the complexity of the resulting models. We do not train any SVM, because the training time is larger than 10 minutes.
classifiers = [KNeighborsClassifier(3),
KNeighborsClassifier(5),
KNeighborsClassifier(10),
DecisionTreeClassifier(max_depth=5),
DecisionTreeClassifier(max_depth=10),
DecisionTreeClassifier(max_depth=20),
RandomForestClassifier(n_estimators=1000, max_depth=3),
RandomForestClassifier(n_estimators=1000, max_depth=5),
LogisticRegression(max_iter=100000),
GaussianNB(),
MLPClassifier(hidden_layer_sizes=(100, 100, 100),
max_iter=10000, activation='relu'),
MLPClassifier(hidden_layer_sizes=(100, 100, 100),
max_iter=10000, activation='tanh')]
clf_names = ["Nearest Neighbors (k=3)",
"Nearest Neighbors (k=5)",
"Nearest Neighbors (k=10)",
"Decision Tree (Max Depth=5)",
"Decision Tree (Max Depth=10)",
"Decision Tree (Max Depth=20)",
"Random Forest (Max Depth=3)",
"Random Forest (Max Depth=5)",
"Logistic Regression",
"Gaussian Naive Bayes",
"MLP (RelU)",
"MLP (tanh)"]
scores_micro = dict()
scores_macro = dict()
scores_mcc = dict()
for name, clf in zip(clf_names, classifiers):
print("fitting classifier", name)
clf.fit(X_train, Y_train)
print("predicting labels for classifier", name)
Y_pred = clf.predict(X_test)
scores_micro[name] = precision_recall_fscore_support(
Y_test, Y_pred, average="micro")
scores_macro[name] = precision_recall_fscore_support(
Y_test, Y_pred, average="macro")
scores_mcc[name] = matthews_corrcoef(Y_test, Y_pred)
scores_micro_df = pd.DataFrame(scores_micro, index=[
'precision (micro)', 'recall (micro)', 'fscore (micro)', 'support'])
scores_micro_df = scores_micro_df[0:3] # drop support
scores_macro_df = pd.DataFrame(scores_macro, index=[
'precision (macro)', 'recall (macro)', 'fscore (macro)', 'support'])
scores_macro_df = scores_macro_df[0:3]
scores_df = pd.concat([
scores_macro_df,
scores_micro_df,
pd.DataFrame(scores_mcc, index=['MCC'])
])
We now look at the scores.
scores_df
We can see that $k$-Nearest Neighbor yields the best results with $k=3$ and the Decision Tree and Random Forest perform better with larger depths. Morepver RelU works better than the tanh for the MLP. Logistic Regression and Gaussian Naive Bayes are clearly inferior to the best performing approaches. We now re-run the experiement. We drop the Logistic Regression, the inferior combinations of $k$ and Max Depth, and the MLP with tanh. Moreover, we consider lower values for $k$ and larger for the Max Depth, because the results may further improve. Please note that due to this second round of tuning, our test data is now validation data instead. If you perform additional tuning due to results on the test data even once, this means that you would actually need new test data.
classifiers = [KNeighborsClassifier(1),
KNeighborsClassifier(2),
KNeighborsClassifier(3),
DecisionTreeClassifier(max_depth=20),
DecisionTreeClassifier(max_depth=40),
DecisionTreeClassifier(max_depth=60),
RandomForestClassifier(n_estimators=1000, max_depth=5),
RandomForestClassifier(n_estimators=1000, max_depth=10),
RandomForestClassifier(n_estimators=1000, max_depth=20),
MLPClassifier(hidden_layer_sizes=(100, 100, 100),
max_iter=10000, activation='relu')]
clf_names = ["Nearest Neighbors (k=1)",
"Nearest Neighbors (k=2)",
"Nearest Neighbors (k=3)",
"Decision Tree (Max Depth=20)",
"Decision Tree (Max Depth=40)",
"Decision Tree (Max Depth=60)",
"Random Forest (Max Depth=5)",
"Random Forest (Max Depth=10)",
"Random Forest (Max Depth=20)",
"MLP (RelU)"]
scores_micro = dict()
scores_macro = dict()
scores_mcc = dict()
for name, clf in zip(clf_names, classifiers):
print("fitting classifier", name)
clf.fit(X_train, Y_train)
print("predicting labels for classifier", name)
Y_pred = clf.predict(X_test)
scores_micro[name] = precision_recall_fscore_support(
Y_test, Y_pred, average="micro")
scores_macro[name] = precision_recall_fscore_support(
Y_test, Y_pred, average="macro")
scores_mcc[name] = matthews_corrcoef(Y_test, Y_pred)
scores_micro_df = pd.DataFrame(scores_micro, index=[
'precision (micro)', 'recall (micro)', 'fscore (micro)', 'support'])
scores_micro_df = scores_micro_df[0:3] # drop support
scores_macro_df = pd.DataFrame(scores_macro, index=[
'precision (macro)', 'recall (macro)', 'fscore (macro)', 'support'])
scores_macro_df = scores_macro_df[0:3]
scores_df = pd.concat([
scores_macro_df,
scores_micro_df,
pd.DataFrame(scores_mcc, index=['MCC'])
])
We now look at the scores to see if the other parameters further improved the scores to see which classifier performs best.
scores_df
We observe that 1-Nearest Neighbor clearly performs best overall, with the best values for MCC, F-Score (both micro and macro), recall (both micro and macro), and precision (micro). Only for precision (macro) is slightly lower than for the $2$-Nearest Neighbor model and the Random Forest with Max Depth 10. We also observe that the Decision Tree does not further improve with deeper trees than 20. The Random Forest also performs best with depth 20. The Random Forest performs second best overall.
We now compare the confusion matrix of the 1-Nearest Neighbor classifier with the confusion matrix of the Random Forest, with the hope that we may see an indication why the Random Forest does not achieve the same performance as the nearest neighbor algorithm.
from sklearn.metrics import ConfusionMatrixDisplay
fig, axes = plt.subplots(1, 2, figsize=(12, 7))
ConfusionMatrixDisplay.from_estimator(classifiers[0], X_test, Y_test, cmap=plt.cm.Blues, ax=axes[0])
ConfusionMatrixDisplay.from_estimator(classifiers[8], X_test, Y_test, cmap=plt.cm.Blues, ax=axes[1])
axes[0].set_title(clf_names[0])
axes[1].set_title(clf_names[8])
plt.show()
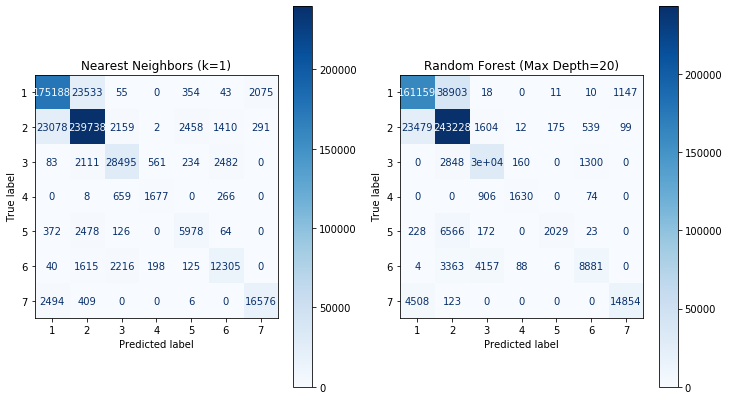
This detailed view of the performance shows us that the performance difference is mainly due to the classes 5 and 6. For both classes, the 1-Nearest Neighbor is much better than the random forest. For all other classes, the performance is comparable.